
#3 – Как работает машинное обучение изнутри?
Видеоурок

Что происходит внутри модели?
Когда вы слышите «машинное обучение», за этим обычно стоит очень простая цепочка: данные → модель → предсказание. Модель — это как математическая формула или алгоритм. Она учится находить закономерности в данных и использовать их для предсказания результата на новых примерах.
Представьте, что вы хотите научить программу отличать медведей от слонов. Вы показываете ей множество картинок, и к каждой прикладываете подпись: «медведь» или «слон». Эти изображения — входные данные, а подписи — это цель, или по-другому — target. Модель анализирует изображения, находит общие черты (например, цвет, форму, наличие шерсти) и постепенно учится определять, кто есть кто.

Что такое признаки и цель?
В машинном обучении каждое наблюдение состоит из признаков (features) и цели (target). Признаки — это факты или характеристики, описывающие объект. Например, если мы хотим предсказывать цену квартиры, признаки могут быть: площадь, количество комнат, район, наличие балкона и т.д. Цель — это то, что мы хотим предсказать. В этом случае — цена.
Важно понимать, что признаки должны быть понятными и полезными для модели. Если вы дадите модели бессмысленные или случайные признаки, она ничему не научится. Поэтому в реальных проектах очень много времени уходит на подбор и подготовку признаков.
Обучение и тестирование
После того как у нас есть данные, мы делим их на две части: обучающую выборку и тестовую выборку. Обучающая — та, на которой модель учится. Тестовая — это данные, которых модель ранее не видела. С их помощью мы проверяем, насколько хорошо она справляется.
Это как в школе: вы сначала решаете задачи по учебнику — это обучающая часть. А потом пишете контрольную, где задачи похожие, но новые — это тестовая часть. Если вы хорошо усвоили материал, то справитесь и на контрольной.
Что такое loss и accuracy?
Когда модель делает предсказание, ей нужно понять — правильно оно или нет. Для этого существует метрика ошибки, называемая втрата или loss. Это просто число, показывающее, насколько сильно предсказание модели отличается от правильного ответа.
Цель обучения — минимизировать эту ошибку, сделать так, чтобы предсказания модели были как можно ближе к реальным значениям.
Существует также метрика accuracy — точность. Она используется в задачах классификации. Например, модель должна определить, является ли письмо спамом. Если из 100 писем модель правильно классифицировала 90, то точность составит 90%. Чем выше точность — тем лучше.
Что такое эпохи?
Когда модель обучается, она не делает это за один проход по данным. Обычно данные показываются модели много раз, и каждый полный проход по обучающей выборке называется эпохой.
С каждой эпохой модель немного улучшается: анализирует свои ошибки, подстраивает внутренние параметры и старается предсказывать точнее. Но важно не переборщить с количеством эпох — если обучать слишком долго, модель может начать запоминать конкретные примеры и плохо работать на новых. Это называется переобучение.
Градиентный спуск — простыми словами
Теперь один из самых интересных моментов — как модель обучается? То есть как она понимает, в каком направлении нужно двигаться, чтобы стать лучше? Для этого используется метод, называемый градиентный спуск.
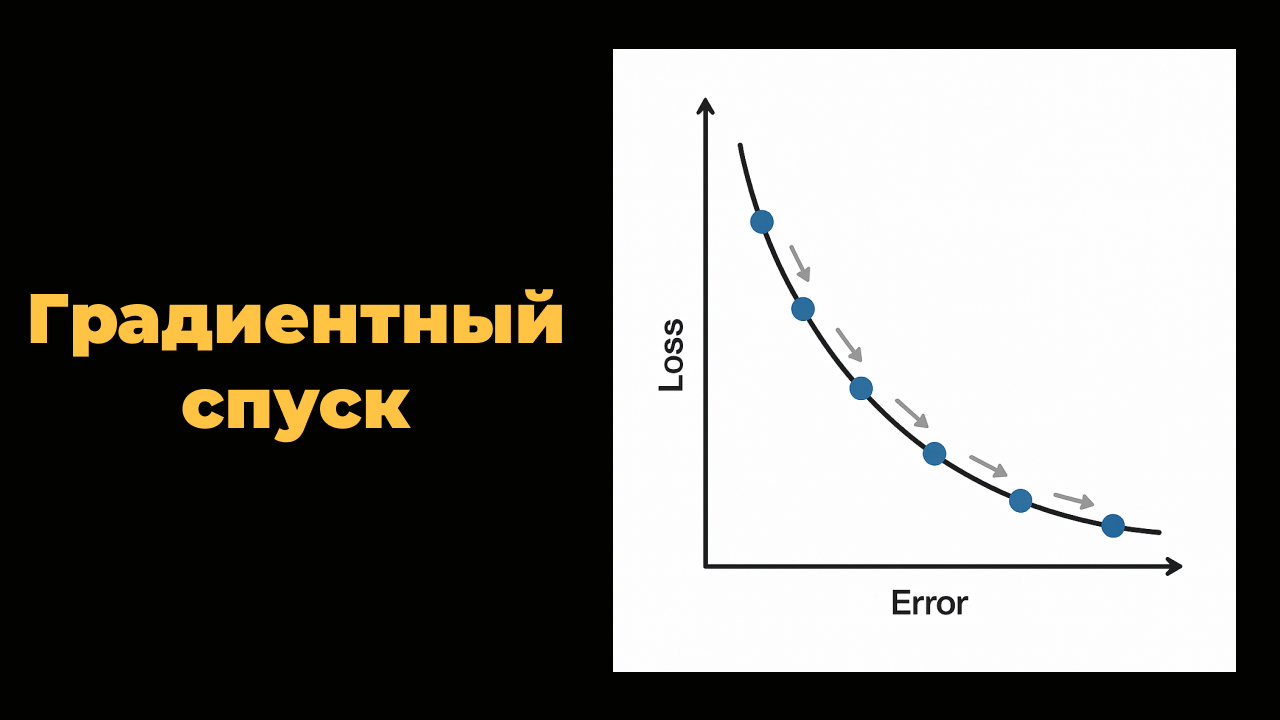
Представьте, что вы стоите на вершине холма и хотите спуститься в самую низкую точку. Но у вас закрыты глаза. Единственное, что вы умеете — почувствовать, в какую сторону земля наклоняется больше всего, и сделать один маленький шаг туда. Потом снова почувствовать и снова сделать шаг. Так, шаг за шагом, вы дойдёте до самой низкой точки.
В обучении моделей происходит то же самое. Модель делает предсказание, вычисляет ошибку (loss), а затем немного корректирует свои внутренние параметры так, чтобы ошибка уменьшилась. Этот процесс повторяется множество раз, и со временем модель становится всё точнее. Это и есть градиентный спуск.
Задание к уроку
Необходимо оформить подписку на проект, чтобы получить доступ ко всем домашним заданиям
Также стоит посмотреть






