
Почему Apache Kafka набирает популярность? Полное руководство для нови
В последние годы Apache Kafka стала одной из самых популярных технологий для обработки данных в реальном времени. Эта платформа получила широкое признание за счет высокой производительности.
Однако для многих новичков в программировании понимание того, что делает Kafka уникальной, может быть сложной задачей. В этой статье мы разберём, что такое Kafka, как она работает, зачем она нужна и почему она становится всё более популярной в современном программировании.
Что такое Apache Kafka?
Apache Kafka — это распределённая система для обработки потоков данных. Она была разработана в компании LinkedIn и стала открытым проектом под эгидой Apache Software Foundation в 2011 году. Изначально Kafka была создана для передачи сообщений между различными системами в реальном времени, но со временем её возможности значительно расширились.
В простых словах, Kafka позволяет передавать данные из одного места в другое надёжно и эффективно. Её основная задача — обработка потоков данных в реальном времени, что делает её идеальной для больших и динамичных систем, таких как социальные сети, онлайн-банкинг, платформы для аналитики данных и многое другое.
Как работает Kafka?
Чтобы понять, как работает Kafka, давайте рассмотрим её ключевые компоненты:
- Продюсеры (Producers) — это программы или сервисы, которые генерируют и отправляют данные в Kafka. Эти данные могут быть разными: логи, метрики, информация о покупках и многое другое.
- Брокеры (Brokers) — это серверы, которые получают и хранят сообщения от продюсеров. Kafka использует несколько брокеров для распределённого хранения данных, что делает систему надёжной и масштабируемой.
- Темы (Topics) — это каналы, через которые передаются сообщения. Например, у вас может быть отдельная тема для пользовательских действий на сайте и другая тема для данных о продажах.
- Консьюмеры (Consumers) — это программы или сервисы, которые «читают» сообщения из тем. Эти данные могут использоваться для анализа, создания отчетов или принятия решений в реальном времени.
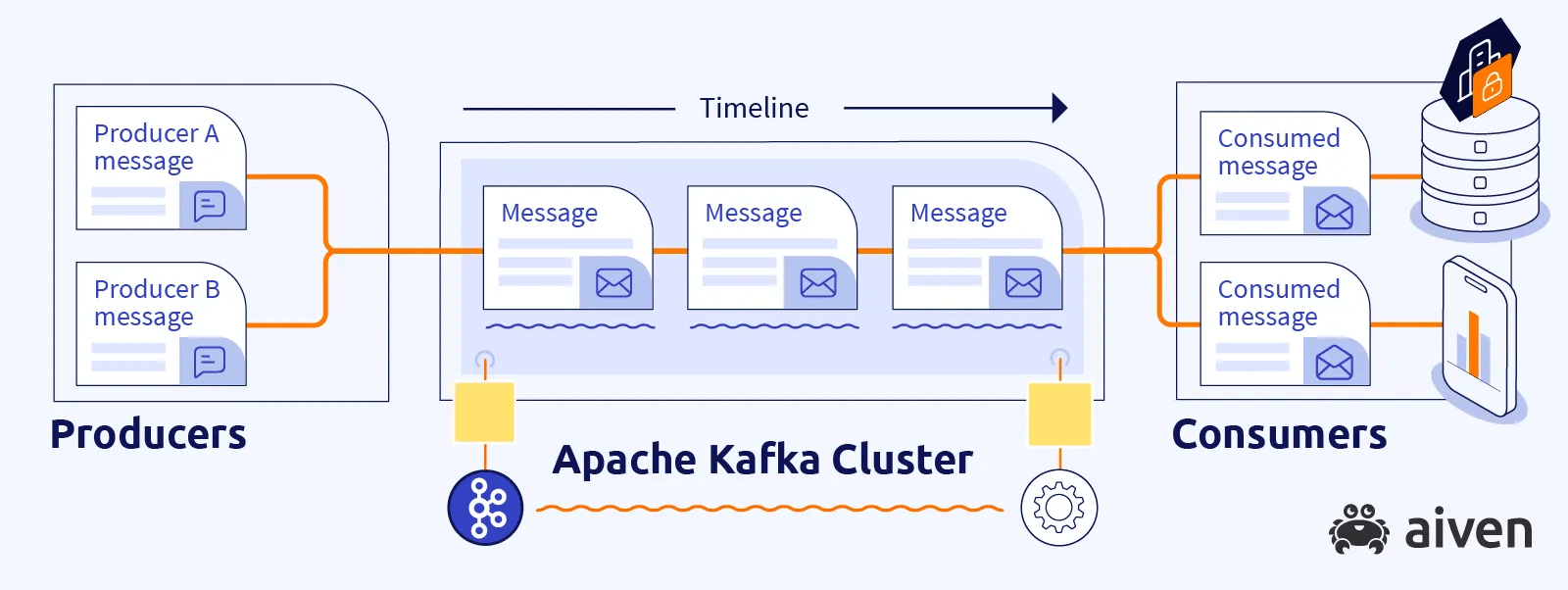
Kafka работает по принципу "publish-subscribe" (публикация-подписка). Продюсеры публикуют сообщения в темы, а консьюмеры подписываются на эти темы и получают данные. Такой подход позволяет эффективно обрабатывать большие объёмы информации, даже если данные поступают из разных источников и должны быть распределены между множеством потребителей.
Зачем нужна Apache Kafka?
Рассмотрим основные случаи использования Kafka:
- Обработка данных в реальном времени. Одним из ключевых преимуществ Kafka является её способность обрабатывать большие объёмы данных в реальном времени. Это особенно важно для таких приложений, как системы мониторинга, интернет-магазины и социальные сети, где важно моментально реагировать на действия пользователей.
- Сбор и передача логов. В большинстве современных приложений генерируется огромное количество логов. Kafka позволяет эффективно собирать, передавать и хранить эти данные, обеспечивая централизованную систему управления логами.
- Интеграция между различными системами. Kafka может использоваться для соединения разных систем и приложений, помогая им обмениваться данными. Например, это может быть полезно для интеграции интернет-магазина с системой учёта товаров, платежными системами и службами доставки.
- Создание потоков данных для аналитики. В условиях современного бизнеса данные — это один из самых ценных ресурсов. С помощью Kafka компании могут собирать, обрабатывать и анализировать данные в реальном времени для принятия обоснованных решений.
- Масштабируемость и высокая доступность. Kafka поддерживает горизонтальное масштабирование. Это означает, что вы можете добавлять новые серверы (брокеры) в свою систему, чтобы обрабатывать ещё большие объёмы данных, не снижая производительность. Благодаря дублированию данных между брокерами Kafka также обеспечивает высокую доступность системы.

Почему Apache Kafka набирает популярность?
Теперь, когда мы разобрались с основными функциями Kafka, давайте рассмотрим, почему эта технология становится всё более популярной:
- Kafka способна обрабатывать миллионы сообщений в секунду, что делает её одной из самых производительных систем для передачи данных. Это особенно важно для компаний, которые работают с большими объёмами данных и нуждаются в быстрой обработке.
- В современном мире данные продолжают расти в геометрической прогрессии. Kafka легко масштабируется, что позволяет компаниям добавлять новые узлы (брокеры) для обработки данных без изменения существующей инфраструктуры.
- Kafka использует дублирование данных и механизмы восстановления после сбоев, что обеспечивает её надёжность. Даже если один из серверов выйдет из строя, данные не будут потеряны, и система продолжит работать.
- Kafka можно использовать для решения множества задач, будь то сбор логов, обработка данных, аналитика в реальном времени или интеграция между системами. Её гибкость и универсальность делают её подходящей для самых разных сценариев использования.
- Как открытая платформа с активным сообществом разработчиков, Kafka постоянно обновляется и улучшается. Это обеспечивает доступ к новым функциям и решениям для эффективного использования платформы.
Примеры использования Kafka в реальном мире
Многие крупные компании уже успешно используют Apache Kafka для своих нужд. Вот несколько примеров:
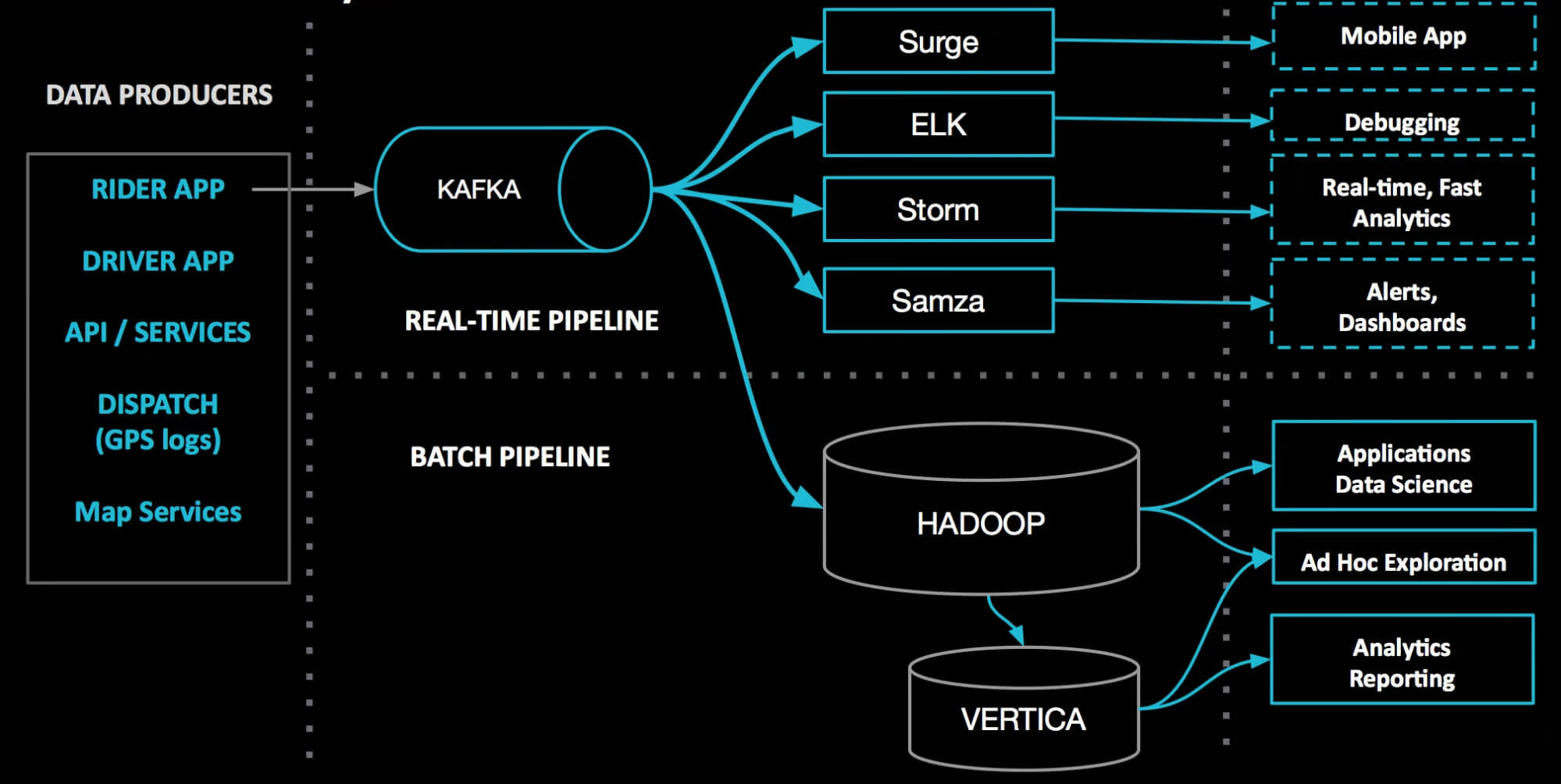
- LinkedIn. Именно LinkedIn разработала Kafka для решения задач по обработке данных в реальном времени. Сегодня платформа используется для передачи миллиардов событий ежедневно, таких как просмотры профилей, взаимодействие с контентом и прочее.
- Netflix. Компания использует Kafka для мониторинга своих сервисов и обработки событий в реальном времени, что позволяет ей обеспечивать надёжность работы платформы и улучшать качество контента для пользователей.
- Uber. Uber использует Kafka для обработки данных о поездках, водителях и клиентах в реальном времени, что позволяет компании обеспечивать оперативную работу сервиса и улучшать алгоритмы маршрутизации.
Как начать использовать Kafka?
Если вы хотите начать использовать Kafka в своём проекте, есть несколько шагов. Kafka поддерживает множество платформ, включая Linux, macOS и Windows. Официальная документация Apache Kafka предоставляет подробные инструкции по установке и настройке системы.
Разберитесь с тем, как работают продюсеры, брокеры, консьюмеры и темы. Понимание этих компонентов позволит вам эффективно использовать платформу. Kafka поддерживает множество библиотек и коннекторов для интеграции с различными языками программирования, такими как Java, Python и .NET.
После того как вы настроили Kafka, протестируйте её работу на реальных данных, чтобы убедиться, что система работает надёжно и эффективно.
Заключение
Apache Kafka — это мощная и гибкая платформа для обработки потоков данных в реальном времени, которая набирает популярность благодаря своим уникальным возможностям. Её высокая производительность, надёжность и масштабируемость делают её незаменимой для современных приложений, работающих с большими объёмами данных. Независимо от того, работаете ли вы в сфере аналитики, онлайн-торговли или облачных вычислений, Kafka может стать важной частью вашего стека технологий.
Для новичков в программировании Kafka может показаться сложной, но её основные принципы довольно просты. Поняв, как работают ключевые компоненты, такие как продюсеры, брокеры и консьюмеры, вы сможете эффективно использовать эту технологию в своих проектах.
Больше интересных новостей
 Лучшие сайты, созданные на C# ASP .NET
Лучшие сайты, созданные на C# ASP .NET
 11 классных веб-ресурсов с применением искусственного интеллекта
11 классных веб-ресурсов с применением искусственного интеллекта
 Искусственный интеллект: чего ожидать в 2023 году
Искусственный интеллект: чего ожидать в 2023 году
 Интерпретируемые и компилируемые языки: какая тут разница?
Интерпретируемые и компилируемые языки: какая тут разница?
